
SharePoint 2013: Der ewig laufende Crawl
Die Funktionalitäten des SharePoint Servers werden einerseits von Webanwendungen, den Web Applications, betrieben. Auf diesen laufen die Webseitensammlungen - und damit die Webseiten des SharePoint Servers. Hintergründig laufen Dienstanwendungen, die Service Applications. Diese sind für bestimmte Funktionalitäten verantwortlich.
Die Suchdienstanwendung
Eine dieser Dienstanwendungen ist die Suchdienstanwendung (Search Service Application). Sie ist für die Suchfunktion des SharePoints verantwortlich. Mit dieser Suche ist es möglich, nicht nur die Oberfläche der SharePoint Webseiten, sondern auch die auf dem SharePoint abgelegten Dokumente nach Suchbegriffen zu durchleuchten. Um die Suche möglichst aktuell zu halten, wird der Inhalt der Webseiten daher in regelmäßigen Abständen durchforstet. Diese Durchforstungen oder "Crawls" sind je nach Größe der SharePoint Umgebung mitunter zeitintensiv.
Der ewig laufende Crawl
Nicht selten dauert eine vollständige Durchforstung (Full Crawl) mehrere Tage. In manchen Fällen endet der Crawl überhaupt nicht mehr. Ein Blick in die Sharepoint Unified Logging Service (ULS) oder Event Logs gibt vage Hinweise. Bevor man sich dazu entschließt den Crawl abzubrechen, weil er schon seit langer Zeit läuft, lohnt es sich jedoch unbedingt einmal in die Logs zu schauen. Falls keine ständig wiederholenden gleichen Fehlermeldungen dokumentiert sind, sollte man dem Crawl Zeit lassen. Natürlich spielt die Größe der Inhaltsdatenbank, also die Anzahl und Größe an Daten, eine entscheidende Rolle dabei, wie lange ein Crawl dauert. Die Ursachenforschung für nicht endende Crawls ist schwer, zeitintensiv und - das behaupte ich - nicht sehr sinnvoll. Die Lösung des Problems ist in den meisten Fällen: Löschen und Neuerstellen der Suchdienstanwendung!
Daher folgt nun eine Schritt-für-Schritt Anleitung zum Löschen und Neuerstellen der Suchdienstanwendung.
Löschen der bestehenden Suchdienstanwendung
Zunächst muss die alte Dienstanwendung gelöscht werden. Dazu benötigt man ein Benutzerkonto, das Mitglied der Gruppe Farmadministratoren ist.
Zunächst öffnet man am SharePoint Server die Sharepoint 2013 Management Shell und führt folgende Befehle aus:
$spapp = Get-SPServiceApplication –Name
Standardmäßig lautet der Name „Search Service Application“. Falls dies nicht der Fall sein sollte, lassen Sie sich die Namen der Dienstanwendungen mit folgendem Befehl ausgeben:
Get-SPServiceApplication | fl name
Löschen Sie die Anwendung nun mit diesem Befehl
Remove-SPServiceApplication $spapp –RemoveData
Erstellen der neuen Suchdienstanwendung
Es wird empfohlen, dass für die Suchdienstanwendung eigene Benutzerkonten im Active Directory erstellt werden. Zwei sind dafür ausreichend. Auf dem Domain Controller werden diese unter Active Directory Users and Computers erstellt. Nennen Sie diese beispielsweise SearchService und ContentAccess.
Diese beiden Konten müssen nun in der Central Administration des Sharepoints registriert werden. Dazu navigiert man zu Security -> General Security -> Configure managed Accounts -> Register Managed Account.

Geben Sie dort Benutzernamen (mit Domäne) und Passwort an.
Nun kann die Suchdienstanwendung erstellt werden. Dafür navigiert man über die Central Administration zu ManageService Applications. Unter New kann die Suchdienstanwendung erstellt werden.
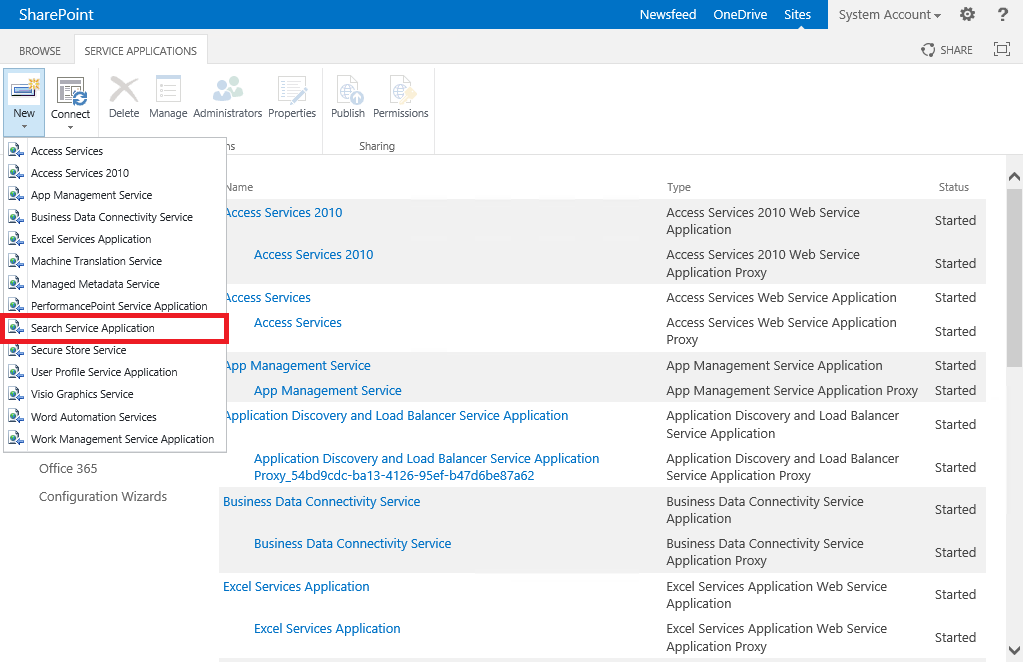
Geben Sie unter Search Service Account den Account SearchService an. Erstellen Sie als nächstes neue Application Pools unter Application Pool for Search Admin Web Service und Application Pool for Search Query and Site Settings Web Services. Unter Configurable geben Sie jeweils den Benutzer SearchService an. Schließen Sie den Dialog mit OK ab.
Nun muss die neu erstellte Application konfiguriert werden. Öffnen Sie dazu das Fenster Search Administration. Wählen Sie unter Default content access account den Benutzer, der vom Crawler benutzt wird, um auf dem SharePoint Dateien zu durchsuchen. Das bedeutet, dass dieses Benutzerkonto so viele Leserechte wie möglich auf dem SharePoint haben sollte. Hierfür ist das vorhin erstellte Benutzerkonto ContentAccess gedacht. Achten Sie darauf, dass dieses Konto möglichst viele Leserechte erhält.
Es wird automatisch eine Inhaltsquelle bzw.Content Source erstellt. Wählen Sie die automatisch erstellte Inhaltsquelle aus und geben Sie eine Startadresse an. Beim Konfigurieren von mehreren Inhaltsquellen ist zu beachten, dass sich die Startadressen nicht überschneiden dürfen.
Um die Neuerstellung abzuschließen, sollte ein Full Crawl ausgeführt werden. Damit wird die gesamte Inhaltsquelle durchforstet und indexiert. Um Ressourcen zu sparen, wird empfohlen, nach dem ersten Full Crawl, nur noch inkrementelle oder kontinuierliche Crawls auszuführen. Mit diesen werden im Gegensatz zum Full Crawl nur neue bzw. geänderte Inhalte durchforstet.
Referenzen
https://technet.microsoft.com/en-us/library/gg502597.aspxhttp://sharepointwoo.com/the-never-ending-crawl-part-1/
- ASP.NET 1
- Active Directory 41
- Administration Tools 1
- Allgemein 60
- Backup 4
- ChatBots 5
- Configuration Manager 3
- DNS 1
- Data Protection Manager 1
- Deployment 24
- Endpoint Protection 1
- Exchange Server 62
- Gruppenrichtlinien 4
- Hyper-V 18
- Intune 1
- Konferenz 1
- Künstliche Intelligenz 7
- Linux 3
- Microsoft Office 11
- Microsoft Teams 1
- Office 365 11
- Office Web App Server 1
- Powershell 21
- Remote Desktop Server 1
- Remote Server 1
- SQL Server 8
- Sharepoint Server 12
- Sicherheit 1
- System Center 10
- Training 1
- Verschlüsselung 2
- Virtual Machine Manager 1
- Visual Studio 1
- WSUS 7
- Windows 10 12
- Windows 8 9
- Windows Azure 4
- Windows Client 1
- Windows Server 24
- Windows Server 2012 7
- Windows Server 2012R2 15
- Windows Server 2016 7
- Windows Server 2019 2
- Windows Server 2022 1
- Zertifikate 4